Austere Challenge 2024: LOGFAS and MNLOGCOP
From March 4-14, the United States European Command (USEUCOM) conducted Exercise Austere Challenge 2024 (AC24) virtually across the European Theater to practice US response to a major fictional crisis. Both military and civilian personnel participated in the exercise which occurred in two phases. In Fall 2023, USEUCOM staff completed the Deliberate Planning phase to increase cohesion and integration across North Atlantic Treaty Organization (NATO) Allies in the European Theater including the US, NATO, and other Allies. Then, in this most recent operation, USEUCOM staff completed the execution phase to coordinate US operations in support of NATO’s defense.
According to an article by USEUCOM, the purpose of this exercise is to “prepare U.S. and NATO forces to operate across the full range of military operations in joint, trans-regional, multi-domain, multi-functional, integrated and contested environments.” This most recent iteration of the AC series of exercises is part of a larger series of exercises planned and executed since the 1990s focused on “training combatant command coordination, command and control and the integration of capabilities and functions across USEUCOM’s headquarters, its component commands, other combatant commands and U.S. government agencies.”
US Army V Corps and 310th Sustainment Command (Expeditionary)
As part of AC24, the US Army V Corps and 310th Sustainment Command (Expeditionary) (ESC) stationed at Fort Knox, Kentucky completed some of the virtual exercise. Several members of Team Joint Enterprise Data Interoperability (JEDI) were onsite during the virtual exercise to assist V Corps and 310th ESC in the use of NATO Logistics Functional Area Services (LOGFAS) and the JEDI Multinational Logistics Common Operating Picture (MNLOGCOP), a capability which helps decision makers to understand logistics and operational data by automating the production of a Recognized Logistics Picture (RLP).

Simultaneously, other Team JEDI members were present in the European Theater to provide support and training for LOGFAS and the JEDI MNLOGCOP leading up to and during the exercise in Kaiserslautern, Germany, where the US Army 21st Theater Sustainment Command (TSC) is headquartered, Wiesbaden, Germany, and Grafenwoehr Training Area, also known as the U.S. Army Garrison Grafenwoehr, a US Army military training base in Germany. The 21st TSC’s JEDI Movement Center Europe (JMCE) serves as the 21st TSC LOGFAS Center of Excellence, effectively leveraging LOGFAS in day-to-day mission support and in US and NATO exercises including AC24.
LOGFAS and MNLOGCOP Successes
Thanks to V Corps, 310th ESC, and those in the European Theater, there were LOGFAS and the JEDI MNLOGCOP successes during AC24. During the exercise, almost one hundred LOGFAS user accounts and almost two hundred JEDI MNLOGCOP user accounts were created for US, British, and Estonian users, representing a greater commitment to the integration of these essential capabilities in a multinational environment. Exercising this capability led to improvements in network interoperability, allowing for the expanded usage of these capabilities in future exercises.
V Corps’ usage of LOGFAS in this exercise marks a significant step towards further integrating US Forces into NATO systems and procedures. V Corps used LOGFAS and the JEDI MNLCOGCOP to simulate the planning, collaboration, and execution of various movement missions throughout the European theater for AC24. They primarily utilized the LOGFAS transportation and movement applications of Effective Visible Execution (EVE) and Coalition Reception Staging Onward Movement (CORSOM). During the exercise, V Corps’ commitment to utilization of these capabilities resulted in their creation of over a thousand missions in EVE and over one hundred custom exercise locations in the LOGFAS Geo Manager. Similarly, those in the European Theater during AC24 utilized LOGFAS and the JEDI MNLOGCOP to effectively simulate and respond to the exercise’s needs. Many future opportunities were identified throughout the exercise that will better improve NATO’s multinational interoperability.
Future Opportunities
Today, the NATO alliance remains a critical pillar of transatlantic security, serving as a forum for political and military cooperation among its members. In the face of evolving security challenges, including Russian aggression, terrorism, and cyber threats, NATO plays a crucial role in promoting stability and security in Europe and beyond. The use of LOGFAS and the JEDI MNLOGCOP during AC24 opened future opportunities for improvement in these capabilities and further expansion of their use by other NATO Nations and Allies. The integration of US Forces into NATO systems, as demonstrated in Austere Challenge 2024 through the use of LOGFAS and the JEDI MNLOGCOP, underscores the enduring commitment of the United States to the alliance.
F-35 Data Interoperability: JEDI-X In Action
The F-35 aircraft are fifth generation, multi service, multi mission, supersonic, stealthy fighter aircraft. There are three service specific variants and many configurations. The variants include Air Force, Navy (aircraft carrier capable), and Marine Corps (short take off and vertical landing (STOVL)). The life cycle management of the F-35 falls under the F-35 Lightning II Joint Program Office whose mission is “to deliver a capable, available, and affordable air system to the warfighter - outpacing key competitors to win tomorrow's high-end fight as we develop, deliver, and sustain war-winning fifth-generation capabilities at high-end fourth-generation costs.”

F-35 Program Logistics Problem
Although the aircraft first flew in 2006, according to a 2022 Breaking Defense article, it has yet to reach Milestone C, authorizing full rate production. Poor logistics support has dogged the program since its inception. The Autonomic Logistics Information System (ALIS) has been highlighted as a cause. Anecdotal evidence is rife with negative stories from the field. The Government Accountability Office (GAO) reported that ALIS “…has faced long-standing challenges, including technical complexity, poor usability, and inaccurate or missing data.”
In addition, ALIS is not interoperable with existing maintenance management systems. This creates the requirement to reenter data manually multiple times. Each time data must be manually entered, the risk of error increases. The JPO is seeking ways to overcome this logistics problem.
The JEDI-X Solution
NEXUS Life Cycle Management (NEXUS) has partnered with Black & Rossi, LLC to explore the use of the Joint Enterprise Data Interoperability (JEDI-X) application to enable interoperability between F-35 maintenance and DOD organic depot level maintenance programs under a larger Commercial Technologies for Maintenance Activities (CTMA) contract, Leveraging Data Analytics.
One of the goals of the most recent work on this project was to produce a limited technical demonstrator (LTD) of the JEDI-X data interoperability platform to show the ability to securely share logistics data in a usable form to decision makers at all levels. This project laid the groundwork for that goal. We developed Business Process Models (BPMs) to guide future progress at Fleet Readiness Center Southeast (FRCSE) and Fleet Readiness Center East (FRCE), two of the Navy’s Fleet Readiness Centers (FRCs) that conduct maintenance, repair, and overhaul of aircraft, engines, components, and support equipment.
Specifically, the BPMs showed how data from a variety of sources could be aggregated and presented to a program manager (PM) to automatically generate their daily production report (DPR). The PMs, specifically at FRCSE, had a data aggregation problem similar to that which plagues the entire F-35 enterprise. This is due to what has been termed "swivel chair" data integration where PMs enter the same data across multiple systems.
Elimination of Swivel Chair Operations
Utilizing the JEDI-X system, this project largely eliminated these swivel-chair operations for the PMs in their DPR. According to sources within FRCSE, the JEDI-X solution, delivered in an all-inclusive presentation format that introduced superior peer-to-peer and subordinate information chains, took what was a 30-minute process and made it the work of seconds. Extrapolated across all the PMs at FRCSE, this JEDI-X solution was a 99% time saver, resulting in increased efficiency and productivity.
The technology developed in this project showed the viability of the shared data concept and the value to be obtained by sharing logistics information throughout the enterprise. This powerful capability will have wide ranging repercussions in the maintenance and sustainment community. Future and continued work with the F-35 JPO will continue to evolve these capabilities within the program and across the enterprise.
How to convert your data to LOGFAS
In response to the digital transformation and complexity of military logistics, the large number and diversity of its members, and to offer a standardized solution to the members, NATO developed the LOGFAS suite of operation enablement tools (click here to discover what is LOGFAS). LOGFAS supports complex military operations, from their planning to execution and sustainment, managing equipment, missions, and personal data in a standardized, independent, and nation-agnostic fashion.
Unified view of data: the LOGFAS data format
Most nations use their own data in their national systems to plan and execute logistics operations and manage sustainment of their forces. NATO developed a standardized system implemented within LOGFAS to support multinational operations. It allows NATO to provide members and partner nations unified and shared views of operations in a way that is understood and meaningful to all parties.
Taking advantage of this standardized system requires each nation to build and maintain processes and reference data to support consistent bi-directional flows of data between national systems and LOGFAS.
These requirements are even more crucial to and complex within nations with larger military offerings to multinational operations.
Building and maintaining the reference datasets is key to this standardization effort: reference dataset contains equivalence tables between national data and NATO ones. These reference datasets are used to translate national data into a LOGFAS format. Reference datasets traditionally include, but are not limited to details about organization, equipment, weapon systems, consumables, personnel, and geographic locations.
Extract and convert reference data from your national systems
 At Nexus, we developed and have implemented the following integration workflow to help you extract and reference data from your national systems to feed LOGFAS:
At Nexus, we developed and have implemented the following integration workflow to help you extract and reference data from your national systems to feed LOGFAS:
- Identify national systems: we help you identify existing national systems containing your existing reference datasets.
- Analyze reference datasets: once located, these datasets are analyzed by our team of experts to evaluate their quality and consistency.
- Associate NATO LOGFAS identifiers to your reference data: , when applicable, we build and deliver your national LOGFAS reference databases (and LOGFAS identifier assignment guidelines to help your organization implement best practices and increase its LOGFAS-readiness.
- Extract and convert data: we understand how to pull data from the system and when applicable, we automate the generation of LOGFAS data.
Your reference data in LOGFAS: a key for interoperability
Once you have extracted and converted reference data from different systems, you now have access to a unified and consistent view in LOGFAS with all of your organization, equipment, weapon systems, consumables, personal, geographic locations, and other critical assets. With your reference data integrated in LOGFAS, you can now build high-fidelity and detailed deployment plans (DDP), with unit movements, their manifest and schedule.
Besides, when you prepare your data for LOGFAS, you are ready to support your allies and partners in your joint and multinational operations by providing accurate, consistent, and high-quality data.
When used in conjunction with JEDI MNLOGCOP, military leaders now have easily accessible high-quality data for sustainment planning and decision support, while also reducing staff’s workload. JEDI MNLOGCOP was used during the Joint Warfighting Assessment 21 to enhance multi-national interoperability.
What are the LOGFAS training options?
Learning LOGFAS from your Home Station or your Home Office?
As the world slowly recovers from the COVID-19 pandemic and the way it has changed our lives, some changes are meant to persist. Among other things, 2020 will be remembered as the year during which working and interacting with others changed. This major shift has required organizations to develop and adapt to new communication strategies and tools (e.g., videoconference platforms) to continue to perform their duties and support services they offer, remotely.
This forced us to rethink our LOGFAS training program and besides our Mobile Training Teams (MTT), to develop the Nexus Remote Learning Capability (RLC) for LOGFAS, offering our customers more flexibility and less risk in planning and executing training events.
What are my LOGFAS training options?
Remote Learning Capability for LOGFAS
With new work environments and constraints, the Nexus RLC comes with two options: self-paced learning and live remote training.
The self-paced learning, offered through an e-learning platform, lets you enjoy video-based LOGFAS classes at your own pace and provides an ideal and flexible solution to busy participants who cannot always attend continuous days of training. It also is ideal for low-volume training, where filling an entire class for an MTT is impractical. This option comes with online quizzes and exercises to validate your newly acquired knowledge and a certificate of completion at the end of the course.
The live remote training is a more traditional option that provides interactive courses with our instructors in live, remote sessions, using a videoconference platform of your choice. The live remote training also gives you access to live feedback from the instructors. This format is an ideal solution for small to large groups but can be constrained by the availability of our instructors.
Mobile Training Teams
The Mobile Training Teams are still available and represent the best choice for groups up to about 25 students in the same physical location. This format allows you to host the training sessions at a facility of your choice, to meet your logistics (we support training worldwide) and security requirements (our training staff holds NATO clearances). This option, however, may be constrained by instructor availability and international travel restrictions.
LOGFAS training summary table
For more information or questions about our options, availability, or pricing please contact us directly.
Demystifying Machine Learning
What is Machine Learning?
Despite a growing popularity and importance over the past decade, Artificial Intelligence (AI) and Machine Learning (ML) can be intimidating concepts to approach because of the vast and complex technical background they rely on and require to be properly implemented. Contrary to popular belief, this technical background is not necessary to understand these concepts, and in this article, we will demystify Machine Learning without diving into any of its mathematical foundations.
AI, a computer science field reported to be initiated in the mid-40s, refers to computerized cognitive behavior (e.g., communication, image processing, and reasoning) and its technical components. One key behavior, which you are experiencing as you read this article, is learning. Learning is about building knowledge, by acquiring and analyzing information, to make better and faster decisions in a predictive manner: the same input should consistently lead to the same output. Machine Learning is about replicating and programming this behavior into artificial agents (e.g., computers, smartphones, IoT devices).
Understanding the different types of learning
Just like us, machines need to learn before they can make decisions. Simply following pre-programmed instructions in the code itself is not learning. Learning happens in a classroom (the machine learning engine), produces a graduate (the machine learning model), and can be achieved in many ways.
The most popular ways to learn are:
- By example, with a supervisor, also known as supervised learning. This method requires an external agent (supervisor) to feed annotated/labeled information and decisions to the machine, to identify correlations between these datasets. This type of learning is task-driven: it requires knowledge of the kind of decisions we expect the machine to deliver.
- On your own: also known as unsupervised learning. This method relies on the machine ability to detect (complex) patterns and anomalies among (often a significantly large set of) unlabeled data. This type of learning is data-driven: unlike supervised learning, we do not anticipate any output, but plan on the machine to deliver new insights about the data.
- Through trial and error: also known as reinforcement learning. This method processes unlabeled data to make decisions that are evaluated by an external agent through a feedback loop that scores these decisions. This score is used by the learner to improve its accuracy over time. This type of learning is error-driven, and it can be used to augment either supervised or unsupervised learning to improve their outputs.
These three types of learning are the most popular and are not restricted to any application domain, but they do not share the same execution model. Supervised learning requires (most of the time) offline training before the machine learning model is ready to be used: this is a traditional student who only learns in the classroom when a supervisor is present. Other forms happen live and incrementally: this is an eternal student who does not require a supervisor and lives in the classroom, constantly discovering new things.
Learning by example
In this section we are going to illustrate ML and walk you through two basic examples. One supervised and one unsupervised.
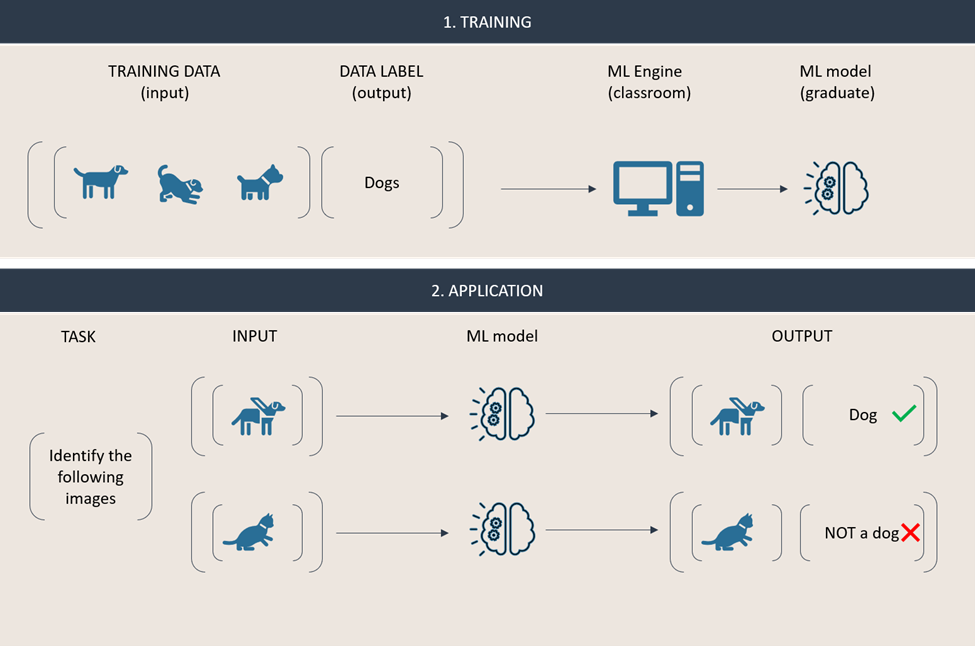
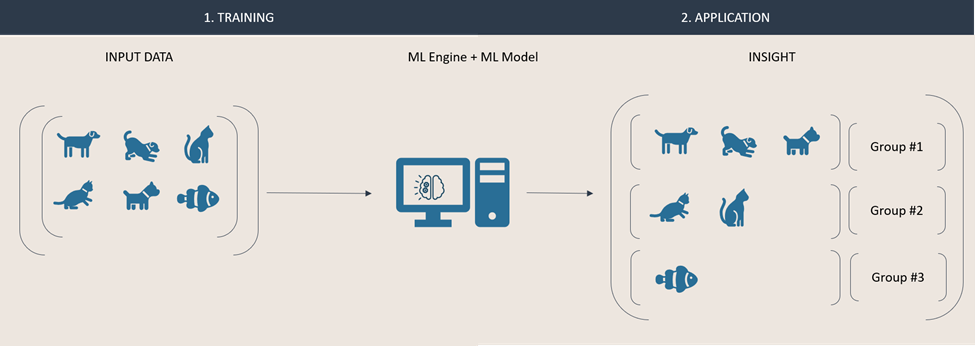
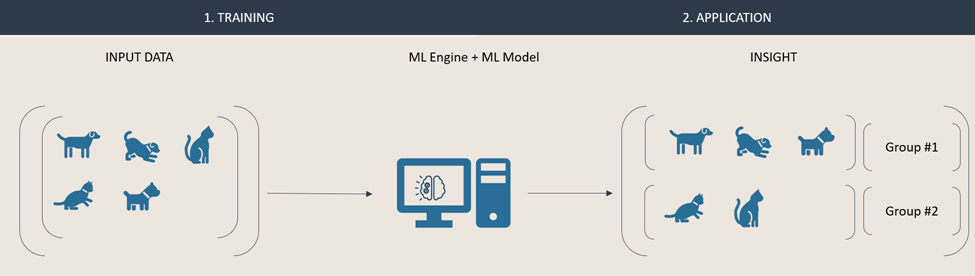
First, using supervised learning we are going to train an ML model to recognize a particular animal. The first step consists of training the model using the ML engine by describing and labeling what we expect the model to recognize. In the engine, the model is taught to identify a correlation between the input given and the conclusion (i.e., the characteristics from our description and the conclusion that an animal is a dog). Once this training has been completed, we can now apply the ML model on new input data that must be classified. In our example, one input will be classified as a dog, while the other will be identified as “not a dog”, because the model could not draw a conclusion based off the correlation it has learned.
In this second example, we are using unsupervised learning to gain insight about a set of animals. That data is fed directly into an engine in which a model groups animals together based on their similarities it can identify. This approach typically results in anonymous groups (i.e., that are not labelled) of similar items.
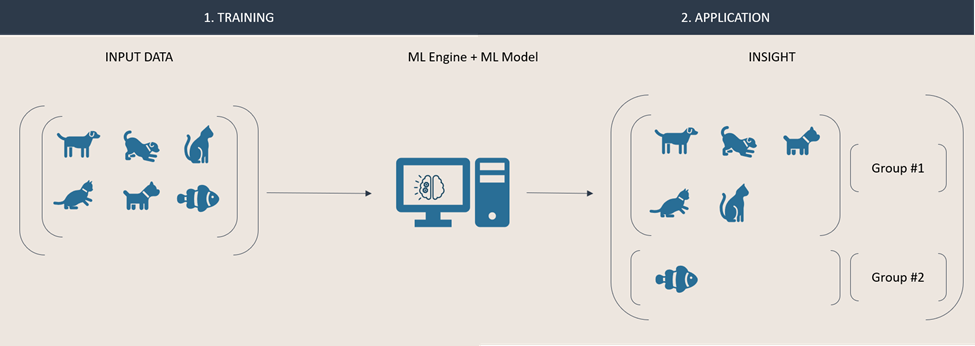
Because unsupervised learning models are eternal students, they can quickly adapt and react to new data. Our input dataset is now enriched with an additional instance. Due to its nature, the model can automatically recreate new groups, based on the new data. These groups will be composed based on the engine and model respective configuration. Both results below are valid outputs. In one, the animals are grouped by their species, in the second result they are grouped by the environment they live in.
Understanding your needs: decision vs insight
Because learning techniques do not yield the same results, it is important to properly define your objectives and needs before picking one. Task-driven supervised learning is an ideal solution to classification and regression problems, in which you already know the problem you want to solve and expect the machine to make decisions for you. Data-driven unsupervised learning is an ideal solution to clustering and association problems, in which you want to explore and learn more about your datasets and expect the machine to give you new insights about your environment.
Conclusion
In this article we have introduced machine learning as the science of artificially replicating one of our most important cognitive behaviors: learning. We then discussed and illustrated its most popular forms: supervised and task-driven, unsupervised and data-driven, and through reinforcement. We ended by highlighting the importance of understanding your needs, before choosing a learning method. In our next article, we will discuss what decision vs. insight means when it comes to logistics.
Nexus is actively implementing AI and ML within our JEDI-X platform to enhance decision support and automation, taking advantage of its semantically rich data.
What is a Logistics COP
Command and Control relies on high-quality logistics and operation data for critical decision making
Military leaders and their staff must make decisions to effectively command and control the diverse capabilities of a joint or multinational force in complex environments. The US Department of Defense Dictionary of Military and Associated Terms defines Command and Control (C2) as:
The exercise of authority and direction by a properly designated commander over assigned and attached forces in the accomplishment of the mission.
During the exercise of this authority and direction, commanders need to make timely and informed decisions. Ultimately, the quality of the decisions strongly depends on the quality of the information that the commander receives as input (situational awareness). To fulfill this mission, information must be current, accurate and contextual. This is possible by enabling data interoperability and workflows from multiple source data systems.
Additionally, commanders need advanced tools to interpret that data and provide situational awareness. These analytics tools, often in the form of maps and dashboards, have intuitive and configurable user interface that can be tailored to the function and staff it supports. These tools are often referred to as Common Operational Picture or COPs.
COP, Logistics COP, RLF
What is a COP?
In Joint Publication 3-0, the US Joint Chiefs of Staff define a Common Operational Picture (COP) as
a single identical display of relevant information shared by more than one command that facilitates collaborative planning and assists all echelons to achieve situational awareness.
This situational awareness is key to making effective decisions despite the fog and friction of operations.
What is a Logistics COP?
A Logistics COP (LCOP or LOG COP), also known as a Recognized Logistics Picture (RLP), is a tool for situational awareness and decision support, specifically for use by logistics personnel. RLP deliver multiple views of equipment, personnel, and supply readiness in greater detail than what is in a Commander’s COP. In an operational context, the RLP allows the logistics staff to optimize available logistics resources in the Joint Operations Area (JOA) and advise or influence the operational commander through the presentation of compelling evidence supported by accurate and timely data.
In an enterprise context, an RLP can be tailored to provide similar visual representations of information to support decisions related to distribution networks, procurements, or positioning of supplies and equipment to support ongoing or emerging operations. Data interoperability is relevant here also, as equipment and materials are typically managed in different information systems based upon which organization manages them, whether they are held in wholesale or retail inventory, or the type of asset (e.g., vehicles, munitions, fuels).
What is an RLF?
A Recognized Logistics Forecast (RLF) does not focus on the current situation but on the future. An RLF uses the current logistic situation (RLP), expected in/out-flows of the JOA, predicted effects of consumption over a defined timeframe, and other related factors to forecast the future logistics situation and resources availability and needs. Using advanced techniques, such as Machine Learning (ML) and Artificial Intelligence (AI), the RLF learns from the past and gives military leaders increasingly accurate predictions of the future situation. An RLF should also be capable of determining the logistics supportability and risks related to multiple operational or enterprise Courses of Action (CoA) to enable logisticians to identify impacts, even second and third order effects from decisions before they are enacted.
These tools are graphically focused products, usually comprised of a mix of geographical and chart-based information, with the ability to interrogate the underlying data when required. They rely on the automated collection, curation, and analysis of data to respond to proposed Maneuver or Logistics COA.

RLP for Multinational Logistics
The JEDI Multinational Logistics Common Operational Picture (MNLOGCOP) is designed to:
- leverage and synchronize data from multiple operational systems
- support multinational data and exercises
- natively compatible with NATO LOGFAS data
- be fully customizable to a user, nation, commodity, operation, or timeframe
- compute metrics or train ML/AI models to provide advanced logistics forecasts
The JEDI MNLOGCOP is a customizable display of relevant information from one or more Command and Nation. Built to natively support LOGFAS, it facilitates collaborative planning to achieve situational awareness, even in multinational environments.
The JEDI MNLOGCOP leverages JEDI-X to integrate and consume data from multiple disparate sources to support even the most complex scenarios. JEDI-X provides structured data to COPs, RLP or to enable an RLF through application of the ML/AI tools that are best suited for the context of the decisions.
Nexus LCM is working with the US Army to implement the JEDI MNLOGCOP capability as an RLP in the Joint Warfighting Assessment series as an enabler for LOGFAS to support embedded multinational Brigades in US Army Divisions
What is LOGFAS
What is LOGFAS?
Logistics Functional Area Services (LOGFAS) is the suite of tools supporting NATO logistics processes for strategic movement and transportation, multinational deployment planning and execution, in-theatre movement scheduling, and sustainment planning. It is developed, maintained and supported by the Service Support and Business Application of NATO Communications and Information Agency (NCIA).
Why is LOGFAS important?
NATO LOGFAS is the cornerstone of multinational and joint interoperability. It integrates and manages logistics information at the enterprise level and across NATO Allies and Partners. It offers data management and analytics capabilities through modules that support planning and execution of logistics operations.
LOGFAS benefits are multifold:
- Enables multinational collaboration with NATO Allies and Partners in the planning and execution of Multinational logistics operations,
- Enables joint collaboration within the joint logistics enterprise,
- Works in degraded mode when connectivity is not available during operations,
- Access to a Common Operational Picture with different capabilities available in one click. For example: simulate the movement planning in LOGFAS, or access real-time and historical dashboard and map with JEDI MNLOGCOP.
How LOGFAS supports the military logistics process
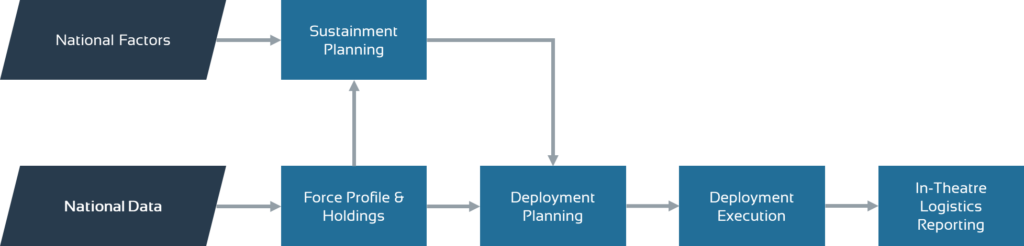
The main logistics process phases as captured in LOGFAS are described below:
- Force Profile and Holdings definition
- Forces definition (including their attributes and organization)
- Items definition (including their attributes and categories)
- Force holdings definition
- Sustainment planning
- Parameters configuration
- Requirements simulation and prediction
- Deployment planning
- Detailed Deployment Plan definition
- Movements & Assets configuration
- Planned cargo manifest definition
- Deployment execution
- Execution mission times visualization
- Actual cargo manifest retrieval
- Movements tracking
- Logistics reporting
- Operational level logistics assessment
- Current state of items monitoring
What are the LOGFAS modules?
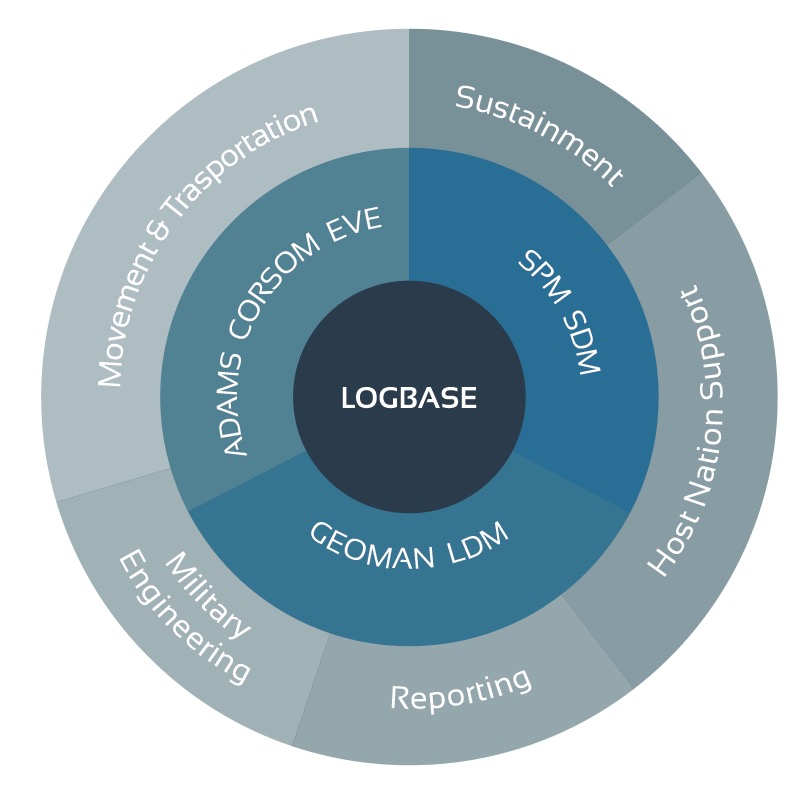
Geographical Manager (GEOMAN)
GEOMAN is used to manage the maps, locations, and networks. GEOMAN locations include air and sea ports. The networks / routes include air, inland waterways, pipelines, rail, road, and sea. Additional infrastructure information such as runways and berths can also be included.
LOGFAS Data Management (LDM)
LDM is used for all data management and data reporting. This includes information about Forces, Items, Assets, and their relationships with one another.
Allied Deployment and Movement System (ADAMS)
ADAMS supports:
- the planning and monitoring of strategic deployments within the desired area of responsibility
- movement coordination and deconfliction
- force and asset assignments and scheduling
Coalition Reception Staging Onward Movement (CORSOM)
Like ADAMS, CORSOM is used to improve reception, staging, and onward movement (RSOM) operations during deployments. CORSOM also includes planning, analysis and deconfliction activities as well as visibility and monitoring of RSOM activities during the deployment.
Effective Visible Execution (EVE)
EVE supports the deployment execution and provides visibility of movement and transportation of assets. EVE also supports the review, prioritization and coordination of movement and transportation.
Supply Distribution Model (SDM)
SDM is a decision-support tool used to test operation resupply and sustainment policies for different scenarios.
Sustainment Planning Model (SPM)
SPM handles Operation Sustainment Planning and packaging, Strategic Stockpile Planning for commodities, and Sustainability Analysis for forces.
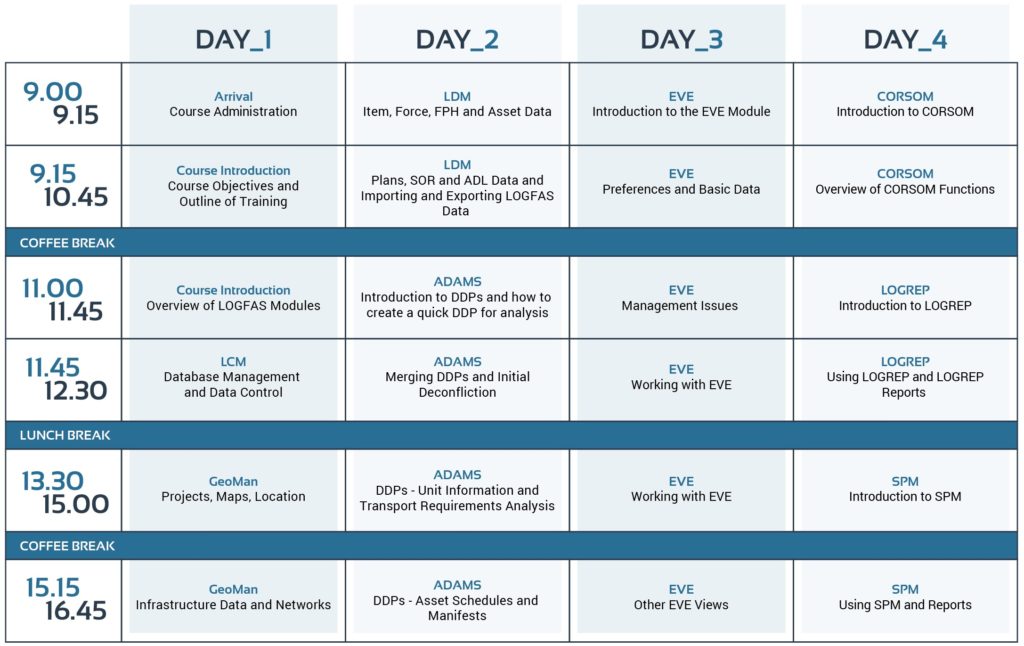
How is a LOGFAS Training organized?
Our training is tailored to your needs, starting with a generic overview followed by additional module training of your choice. All training sessions are live and given by our qualified instructors, in-person or virtually through our online and secure e-learning center.
How to get the user guide and the tools?
Any NATO member can obtain LOGFAS through their appropriate channels.
Do you need help?
Check our LOGFAS Training and Consulting page.

JEDI-X DoD White Paper
The CJCS National Military Strategy identifies the need for interoperability in the Dynamic Force Employment (DFE). It states that
Building a strong, agile, and resilient force requires better interoperability and enhancing the combat lethality and survivability of our allies and partners.
In the US Army, Army Futures Command leads a continuous transformation of Army modernization in order to provide future warfighters with the concepts, capabilities and organizational structures they need to dominate a future battlefield. Joint Enterprise Data Interoperability (JEDI-X) is a capability initially developed by the US Joint Staff to ensure data interoperability that will enable DoD to improve lethality and enable similar logistics data interoperability in the Joint and Coalition space, while supporting the concept of DFE.
Lack of interoperability
DoD, like all large organizations suffers from specialization. Commands use jargon, processes and information systems that are tailored to support their specific functional domains such as research, acquisition, operations, sustainment, and resource management. Non-standardized data models, terminology, reporting formats, and siloed networks limit the sharing and reuse of data by other domains within the Services, Joint commands, industry and Multinational partners performing services for the DoD, or similar roles. This lack of access to accurate, relevant data limits the visibility of available Joint, industry and Multinational resources, the effectiveness of current planning or decision support tools, and hinders the reach for advanced analytics such as Machine Learning and Artificial Intelligence.
Data Interoperability using JEDI-X
Interoperability is the core of Joint and Multinational Operations. The ability to shoot, move, communicate, protect and sustain as a singular unit with partners improves the effectiveness of the DoD across the spectrum of operations. Using common processes, platforms and information systems is the highest level of interoperability. Being able to use common data for planning and decisions, with the ability to transact common resources while operating in national or service systems is a viable alternative when commonality is not possible. Joint Enterprise Data Interoperability (JEDI-X) enables both for the US Army today.
JEDI-X uses a systems engineering approach to identify and map data across current organizational and functional boundaries to unlock it with the necessary context for re-use. It uses non-proprietary information models to ascribe context in data mappings for ease of maintenance and extensibility of data from source to a myriad of target uses. JEDI-X also provides mediation and translation services across these information systems to support transactions, reporting, and visualization of data across systems that otherwise are isolated and opaque.
US Army JEDI-X Implementations
JEDI-X enables the Army and US European Command to re-use US force deployment data from various systems to populate US data in the NATO Logistics Functional Area Services (LOGFAS) suite of tools for coordinating deployment and sustainment of the combined forces. JEDI-X also re-uses LOGFAS data within a Recognized Logistics Picture (RLP) of the combined force, enabling cross-servicing of logistics resources and sustainment planning. Nexus LCM is working with US Army Europe and HQ, Army G4 to:
- Implement the JEDI MNLOGCOP capability as an RLP in the Joint Warfighting Assessment series as an enabler for LOGFAS to support embedded multinational Brigades in US Army Divisions;
- Automate feeds of US Army in-theater movement requests to Multinational Movement Coordination Capabilities, while retaining linkages to the Army Resource Management system of record for payment;
- Enable data feeds from US Transportation Command and theater movements for an integrated view of movements of units and supplies during deployment and sustainment operations to improve coordination of infrastructure, material handling and transportation assets, ensuring prioritization and efficient initial operational capabilities to the Commander;
- Use JEDI-X to integrate an Artificial Intelligence-enabled transportation planning and resourcing tool into NATO operations;
- Continue assessment for a JEDI-X enabled capability for operational units to have visibility and transact multinational supplies and order digital/additive manufactured parts, all without leaving GCSS-Army.
Summary
By simply unlocking and linking existing data for re-use in other processes and systems, JEDI-X can eliminate inefficient searching, cleansing and re-entry of data common in today’s DoD. It can improve the velocity and quality of available data to planners, decision makers, advanced decision support tools of choice and technicians in support of their roles through providing contextually accurate data for re-use across information system and organizational boundaries.