What is Machine Learning?
Despite a growing popularity and importance over the past decade, Artificial Intelligence (AI) and Machine Learning (ML) can be intimidating concepts to approach because of the vast and complex technical background they rely on and require to be properly implemented. Contrary to popular belief, this technical background is not necessary to understand these concepts, and in this article, we will demystify Machine Learning without diving into any of its mathematical foundations.
AI, a computer science field reported to be initiated in the mid-40s, refers to computerized cognitive behavior (e.g., communication, image processing, and reasoning) and its technical components. One key behavior, which you are experiencing as you read this article, is learning. Learning is about building knowledge, by acquiring and analyzing information, to make better and faster decisions in a predictive manner: the same input should consistently lead to the same output. Machine Learning is about replicating and programming this behavior into artificial agents (e.g., computers, smartphones, IoT devices).
Understanding the different types of learning
Just like us, machines need to learn before they can make decisions. Simply following pre-programmed instructions in the code itself is not learning. Learning happens in a classroom (the machine learning engine), produces a graduate (the machine learning model), and can be achieved in many ways.
The most popular ways to learn are:
- By example, with a supervisor, also known as supervised learning. This method requires an external agent (supervisor) to feed annotated/labeled information and decisions to the machine, to identify correlations between these datasets. This type of learning is task-driven: it requires knowledge of the kind of decisions we expect the machine to deliver.
- On your own: also known as unsupervised learning. This method relies on the machine ability to detect (complex) patterns and anomalies among (often a significantly large set of) unlabeled data. This type of learning is data-driven: unlike supervised learning, we do not anticipate any output, but plan on the machine to deliver new insights about the data.
- Through trial and error: also known as reinforcement learning. This method processes unlabeled data to make decisions that are evaluated by an external agent through a feedback loop that scores these decisions. This score is used by the learner to improve its accuracy over time. This type of learning is error-driven, and it can be used to augment either supervised or unsupervised learning to improve their outputs.
These three types of learning are the most popular and are not restricted to any application domain, but they do not share the same execution model. Supervised learning requires (most of the time) offline training before the machine learning model is ready to be used: this is a traditional student who only learns in the classroom when a supervisor is present. Other forms happen live and incrementally: this is an eternal student who does not require a supervisor and lives in the classroom, constantly discovering new things.
Learning by example
In this section we are going to illustrate ML and walk you through two basic examples. One supervised and one unsupervised.
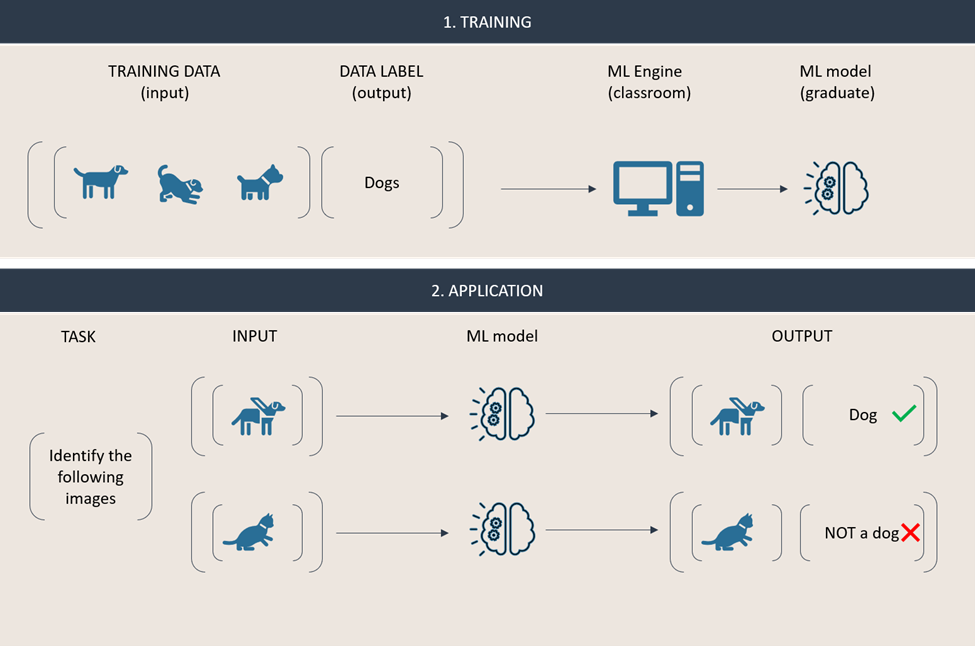
First, using supervised learning we are going to train an ML model to recognize a particular animal. The first step consists of training the model using the ML engine by describing and labeling what we expect the model to recognize. In the engine, the model is taught to identify a correlation between the input given and the conclusion (i.e., the characteristics from our description and the conclusion that an animal is a dog). Once this training has been completed, we can now apply the ML model on new input data that must be classified. In our example, one input will be classified as a dog, while the other will be identified as “not a dog”, because the model could not draw a conclusion based off the correlation it has learned.
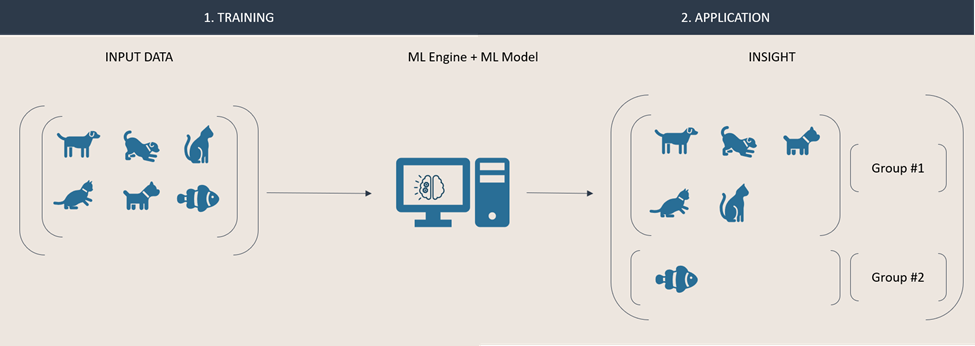
In this second example, we are using unsupervised learning to gain insight about a set of animals. That data is fed directly into an engine in which a model groups animals together based on their similarities it can identify. This approach typically results in anonymous groups (i.e., that are not labelled) of similar items.
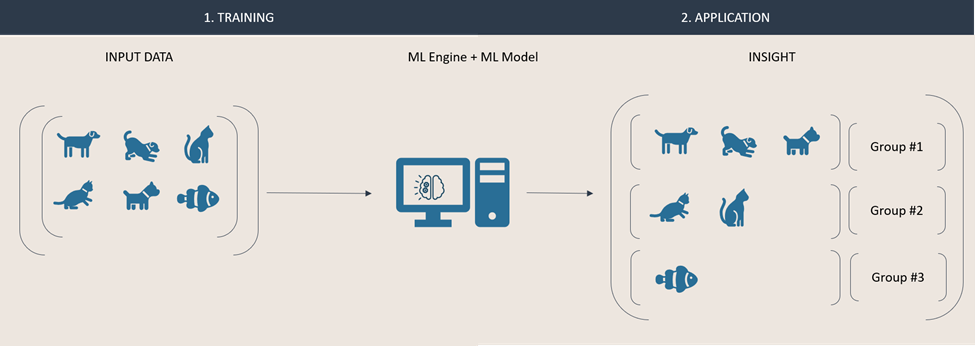
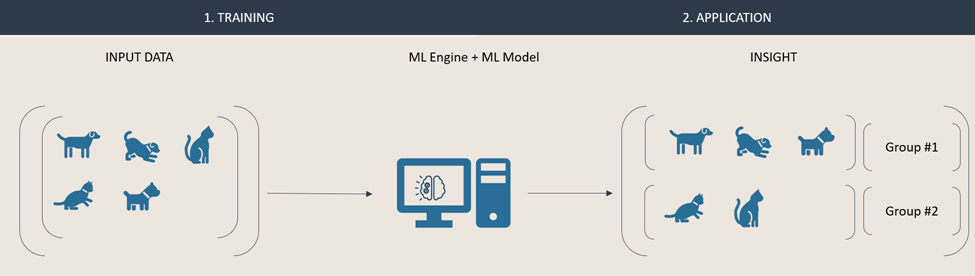
Because unsupervised learning models are eternal students, they can quickly adapt and react to new data. Our input dataset is now enriched with an additional instance. Due to its nature, the model can automatically recreate new groups, based on the new data. These groups will be composed based on the engine and model respective configuration. Both results below are valid outputs. In one, the animals are grouped by their species, in the second result they are grouped by the environment they live in.
Understanding your needs: decision vs insight
Because learning techniques do not yield the same results, it is important to properly define your objectives and needs before picking one. Task-driven supervised learning is an ideal solution to classification and regression problems, in which you already know the problem you want to solve and expect the machine to make decisions for you. Data-driven unsupervised learning is an ideal solution to clustering and association problems, in which you want to explore and learn more about your datasets and expect the machine to give you new insights about your environment.
Conclusion
In this article we have introduced machine learning as the science of artificially replicating one of our most important cognitive behaviors: learning. We then discussed and illustrated its most popular forms: supervised and task-driven, unsupervised and data-driven, and through reinforcement. We ended by highlighting the importance of understanding your needs, before choosing a learning method. In our next article, we will discuss what decision vs. insight means when it comes to logistics.
Nexus is actively implementing AI and ML within our JEDI-X platform to enhance decision support and automation, taking advantage of its semantically rich data.